Bioinformatics @ Systems and Modeling
Welcome to the homepage of our bioinformatics research activities achieved in collaboration with GIGA Research teams and facilities (Interdisciplinary Cluster for Applied Genoproteomics) hosted by the University of Liège.
![]()
HOT NEWS:
On February 15, 2007, we are hosting the kick-off meeting of the IUAP (Inter University Attraction Pole) in "Bioinformatics and Modeling: from genomes to networks".
On the same day we organise the innaugural lecture of the Francqui Chair given by Dr Albert Goldbeter on Systems biology & Cellular rythms.
Here is the content of this page:
- Projects
- ALMA Grid: the virtual Lab over 4 genopoles (2005-...)
- PATROCLES: database of polymorphic miRNA-target interactions (2006-...)
- Biomarker identification and medical diagnosis for inflammatory diseases (2004-...)
- Inference of biochemical networks from heterogeneous and experimental data (2005-...)
- Modeling of treatment response of HIV-infected patients (2005-...)
- Development and applications of image classification methods (2002-...)
- Development of search engine tools for mining biological databases (2004-...)
- Projects starting by end of 2006: IAP network BioMagNET, ARC BIOMOD, BioWIN KEYMARKER (to be documented soon)
- Publications
- Software
- Final thesis
- Open positions and studentships
- Events
Research projects
General research theme
Application, analysis, and development of data mining and modeling techniques for the understanding of processes and the construction of predictive models related to complex biological processes of relevance in medical, agronomical and environmental sciences. In particular, identification of biomarkers and diagnostic/prognostic/treatment response criteria from mixed data sources (mass-spectrometry based proteomics, gene expressions, SNP based genotyping, genetic and proteomic sequences, ontologies, images).
Biomarker identification and medical diagnosis for inflammatory diseases (2004-...)
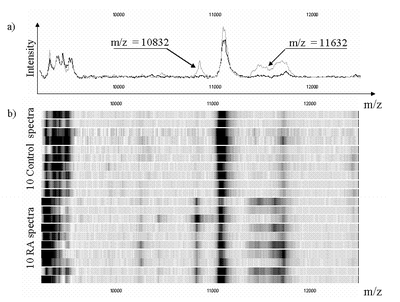
keywords: data mining, machine learning, mass spectra, seldi, crohn, CPOD, Rheumatoide Arthritis, classification, prediction, biomarkers
In collaboration with the laboratory of clinical chemistry and rheumatology (see also project http://www.giga.ulg.ac.be/extranet/txt_databases/PROJETS/MP-I-50_Mal_Mer_Fillet.pdf),
we apply machine learning techniques for the diagnosis of inflammatory diseases (Crohn, Rheumathoid Arthritis, CPOD, …) from proteomic mass spectra.
Databases containing data from healthy and disease patients have been gathered using Surface Enhanced Laser Desorption/Ionisation-Time of Flight-Mass Spectrometry (SELDI-TOF-MS). Several machine learning tools were applied to this
data. The results in terms of accuracy of the diagnostic rule and identified biomarkers are very promising.
Our results are generally superior to those obtained with standard pre- and post-processing techniques used in these applications (peak-detection and p-values based biomarker selection) and are also competitive with existing practice for the diagnosis of these diseases. The methodology is furthermore generic and it could be applied to data obtained from other medical instrumentation like for example microarray.
Contact
Send e-mail to Pierre Geurts, Raphaël Marée, Louis Wehenkel.
Inference of biochemical networks from heterogeneous and experimental data (2005-...)
One of the biggest challenge of post-genomic biology is to understand and determine the complex mechanisms underlying interactions between genes and gene products. In the context of a collaboration with the AMIS-BIO team (Prof. Florence d'Alché-Buc) from the IBISC laboratory at the University of Evry, one of our research interest is to use machine learning techniques for the inference of gene interaction networks from different sources of data, experimental or not. Two kind of approaches are currently investigated:
- First, dynamic modeling approaches that aim at designing detailed dynamic models of gene interactions and then finding model parameters and structure using machine learning techniques. This entails the use of tools such as dynamic bayesian networks, differential equations, kalman filter, etc.
- Second, supervised learning approaches that aim at completing an existing interaction network, focusing on the structure of this network. Our proposal in this direction is based on the use of the output kernel tree method.
Contact
Send e-mail to Pierre Geurts, Louis Wehenkel.
Modeling of treatment response of HIV-infected patients (2005-...)
keywords: data mining, machine learning, clinico-genomic, classification, regression, cd4, prediction, biomarkers
Since October 2005, in collaboration with Prof. Michel Moutschen, this project is about the modeling of treatment response of HIV-infected patients. In such a study, there are a lot of historical patient data and the understanding of the influence of various parameters (such as age, sex, other diseases, initial CD4 level and viral load, type of tritherapy, virus mutations, ...) is not straightforward. Our approach try to combine data mining of clinical and genomic data.
This project is partially funded by a "Bourse du Standard de Liège" grant from "Léon Fredericq" foundation (2005-2007).
Contact
Send e-mail to Raphaël Marée, Louis Wehenkel.
Development and application of image classification methods (2002-...)
keywords: data mining, machine learning, computer vision, image classification
With the improvements in biosensors and high-throughput image
acquisition technologies, life science laboratories are able to
perform an increasing number of experiments that involve the
generation of a large amount of images at different imaging
modalities/scales. However, manual classification
of such an amount of images is time-consuming, repetitive, and could
not always be considered reliable due to experimental conditions,
variable image quality, and human subjectivity or tiredness that lead
to considerable interobserver variations and misclassifications.
It stress the need for computer vision methods
that automate image classification tasks.
Given a set of training images labelled
into a finite number of classes, the goal of an automatic image classification
method is to build a model that will be able to predict accurately the class of
new, unseen images.
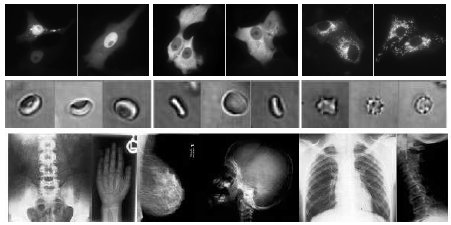
Here at the Systems and Modeling research unit, we developped and adapted a new generic Data Mining approach for image classification. It was successfully applied to several types of image classification problems. In a recent work, our method was successfully evaluated on three datasets of biological images at different imaging modalities/scales: subcellular locations, red-blood cell shapes, human body regions (X-Ray) (see publication MGW06, MGPW05b). Many biomedical applications (e.g. clinical diagnosis, subcellular location proteomics, drug discovery, ...) could benefit from this approach especially since it is directly applicable without tedious adaptation.
See related softwares: PiXiT, and Annotor.
Contact
Send e-mail to Raphaël Marée, Pierre Geurts, Louis Wehenkel.
Development of search engine tools for mining biological databases (2004-...)
keywords: databases, clusters, GenBank, EMBL, NCBI
We develop ad hoc search engine tools to efficiently access (collect, filter, sort, store locally) DNA sequence databases and sequence annotation databases.
These tools are developped in collaboration with Bernard Peers from Genetic and Molecular Biology Unit (CBIG), and with Sébastien Rigali from Center for Protein Engineering, University of Liège. They have motivated the development of our tools for studying genes related to the development of pancreas tissues in Zebra Fish (Danio Rerio) or to search for nucleotides that regulate the genes for a bacteria specie, but the resulting software are general and can be used in the context of similar studies.
Contact
Send e-mail to Samuel Hiard, Raphaël Marée, Louis Wehenkel.
Publications
Publications in bioinformatics
Patents
Identification and use of biomarkers for the diagnosis and the prognosis of inflammatory diseases
Fillet Marianne, De Seny Dominique, Geurts Pierre, Wehenkel Louis, Malaise Michel, Merville Marie-Paule
Patent submitted in US 60/608670, Europe: EP05102885.0, International : PCT/EP2005/054242
Sample of other related publications
A list of journals related to bioinformatics.
Software
PEPITo ®
PEPITo is a generic Data Mining toolbox including various visualization techniques (histograms, scatter plots, dendrograms, ...), statistical methods (p-values, PCA, ...), machine learning methods (ensemble of decision tree based methods, support vector machines, neural networks, nearest neighbors, clustering, ...), database interfaces (MySQL, ODBC, ...), and reporting tools (in pdf, xml, ...). Some of these methods were used in our research for proteomic data classification.
In the near future, we will evaluate and develop new algorithms for modeling biological networks and combining raw data and gene ontologies for specific biomedical applications, and integrate these new techniques in PEPITo.
The software is driven by academic research as well as real-world application needs. It is commercialized by PEPITe but please contact us for research projects.
More details here or send us an e-mail.
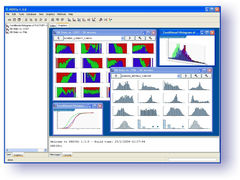
PiXiT
PiXiT is the name of our automatic image classification software. It is directly applicable without tedious adaptation to any kind of image classification problems. It was first successfully applied to: recognition of digits, faces, 3D objects, textures, buildings, general purpose photographs, ... More recently, it was successfully evaluated on a X-Ray image classification problem (see publication MGPW05b and official results).
The software is developped in Java and the documented API allows you to easily integrate it into your environment.
PiXiT is commercialized by PEPITe but please contact us for research projects.
More details here (software executable, publications, ...) or send us an e-mail.
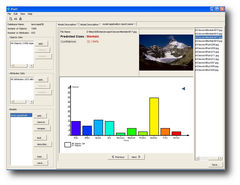
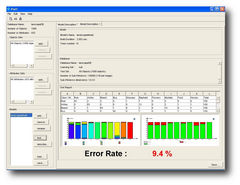
Annotor
Annotor is a manual image annotation software developped in Java that can help scientists to provide ground-truth data (labelled images) to computer vision scientists to help them to develop automatic image annotation or quantification tools. It allows one to annotate images by drawing polygons on top of them (by the means of line-drawing procedure between user-specified successive points and a close operation) and to associate a class to each polygon. Then the software exports different annotation files. The basic format is a XML file that contains a list of polygons defined by a color, a class and a list of points. Another format is a segmentation map image (PNG with transparent background) where each pixel takes the class color it belongs to. In addition to that, Annotor creates a simple text file (for each annotated image) containing the pixel quantities of each class. Also, Annotor can generate directories of cropped images (PNG with transparent background) sorted by class where a cropped image correspond to a polygon. Those different formats can be easily used as input for machine learning.
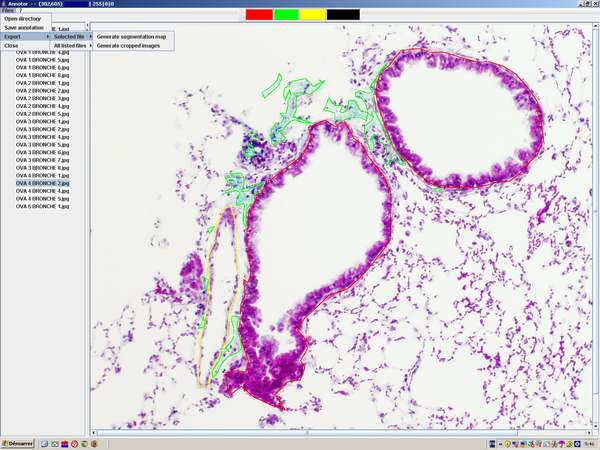
This software was developped by Vincent Botta. More details can be found here.
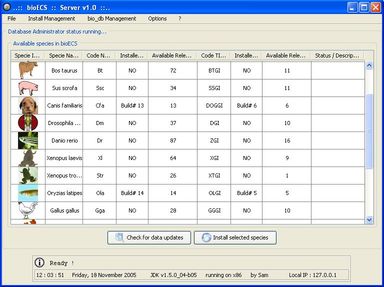
bioECS
The recent progress in molecular biology and in genomics, as well as new developments in terms of data-acquisition devices have allowed the complete sequencing of the human genome, and other species. Consequently, the databases which collect these genomic sequences have grown in an expontential fashion these last years. Among these databases the most used ones are the GenBank and the EMBL databases. The information contained in these databases has become central to the researchers in biology and is therefore important to develop effective bioinformatics tools to help them to efficiently access and analyse this information.
Within this context, the aim of the present work was to develop an ad hoc search engine to help biologists to access (collect, filter, sort, store locally) the data they need in an as easy and time-sparing way possible. The functional specification of the resulting software (called BioECS, for 'Biology Easy Cluster Search') and its user interface have been defined in collaboration with end-users from the 'Centre of Biomedical Integrative Genoproteomics' (CBIG) of the University of Liège. The study which has motivated the development of the software aims at studying genes related to the development of pancreas tissues in Zebra Fish (Danio Rerio), but the resulting software is general and can be used in the context of similar studies. The program provides a solution to biologists in order to isolate EST (Expressed Sequence Tags) clusters corresponding to their research target. A simple Internet surfing software makes this interaction intuitive. The software also provides facilities for saving query results and search criteria for later use. Our solution is based on cross references between several EST databases, namely TIGR and Unigene. The resulting software allows to filter out EST clusters by combining several criteria based on information about tissues, species, and development stages associated to the EST sequences that form the clusters. Each criterion is associated with a "percentage" threshold and the clusters that do not contain enough EST sequences satisfying the criterion are filtered out. The user interface allows to easily access all EST sequences forming the clusters and to browse known GO (Gene Ontology) functions associated to them.
The client/server software architecture is based on JAVA and MySQL. It comprises a 'server' program responsible for the web-based transactions and local caching of information from the public database servers. A 'client' program allows biologists to execute researches. These latter use the JDBC API (Sun MicroSystems) to allow the user to interact in a flexible way with the server, to obtain the selected data items and create reports.
This work was achieved by Benjamin Renwart during his final thesis (2004-2005).
More details here (software executable, source code, javadoc, thesis in pdf) or send us an e-mail.
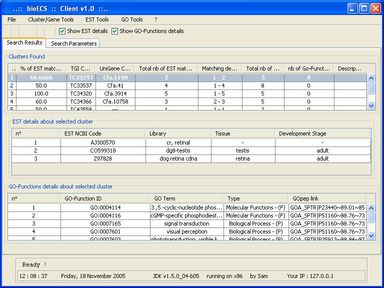
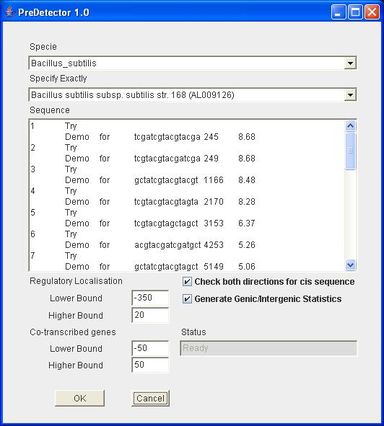
Predetector
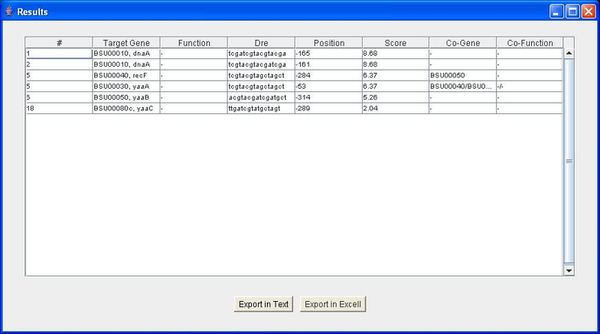
PreDetector is a tool designed for biologists. Its main function is to search for the cis-elements (nucleotides) that regulate the genes for a bacteria specie, assuming that one usually consider that a cis sequence regulates a gene iff it is oriented in the same direction and if it is localised in a user-specified interval regarding to the beginning of the gene. To achieve its function, PreDetector connects to the NCBI server, which provides the information on the genes for a given bacteria. When a cis sequence is considerated as regulating a gene, PreDetector also computes the co-transcribed genes, that is the genes that are located in another user-specified interval regarding to the end of the preceding gene (and this is a recursive process). On user demand, PreDetector also allows to generate statistics containing the percentage of genic and intergenic sequences.
This program was conceived entierely in Java by Samuel Hiard in collaboration with Sébastien Rigali from Center for Protein Engineering, University of Liège.
More details here (software executable, documentation, ...) or send us an e-mail.
Final thesis
Several final thesis have been achieved in the last 5 years relative to bioinformatics (applying and adapting machine learning methods for new biomedical problems, developping software for biologists, ...).
2005-2006
- Classification de séquences biologiques à l'aide de méthodes à base de noyaux, Alaoui Hicham
- Modélisation de la réponse du virus HIV lors de l'arrêt de la trithérapie, Anne-Cécile Gilles
2004-2005
- Développement d'un outil de recherche dans les bases de données génétiques [pdf], Benjamin Renwart.
- Analyse de séquences biologiques par arbres de décision, Antia Blanco Cuesta.
- Apprentissage automatique sur données biomédicales à l'aide de méthodes à base de noyaux, Christophe Grosfils
2002-2003
- Application de l'apprentissage automatique à l'extraction et la gestion de connaissance des DNA Arrays [pdf], François Van Lishout
2000-2001
- Application de l'apprentissage automatique à la localisation de gènes à effets quantitatifs, Estelle Graas.
Open positions & studentships
Please see our "Open positions" page
Events
This browsable calendar (RSS feed) includes some Bioinformatics events (as well as Machine Learning, Computer Vision) worldwide.
Past events related to Bioinformatics at Montefiore Institute:
- F. D'Alché-Buc (Genopole & LaMI UMR 80 42 CNRS), "Machine learning for gene networks modeling", 8th february 2005.
- 4th GIGA Day, "Where life sciences and engineering meet: pratical aspects", University of Liège, 25th March 2004.