2017: Please note I (Raphael Marée) am not involved anymore in the development of PiXiT and this software is not maintained.
I recommend to use our whole Cytomine open-source software instead.
Description
PiXiT is an automatic image classification (or "categorization") software.
It is based on an original methodology combining random subwindow extraction and a machine learning decision tree ensemble technique (extra-trees). This method was proposed by Raphaël Marée during his PhD thesis, in collaboration with Pierre Geurts, Justus Piater, and Louis Wehenkel.
Applications of image classification are multitudinous. Practically, a class could denote a specific objet, a people, a logo or pictogram, a human cell shape, a product defect, a building, an animal species, a medical state, a soil texture, a painting style, a photography theme, a x-ray modality, a soccer team, the stage of a biological process, ... The original method was evaluated on various image classification problems (objects, faces, handwritten digits, buildings, categories, photography, textures), including but not limited to the following databases:
(ZuBuD) (WANG) (COIL-100) (ORL) (MNIST) (OUTEX)
Manual
There is an on-line demo here (plug-in ShockwaveFlash required) that shows one way of using PiXiT. There is also an API documentation available upon request.
Here are more detailed information about how to use PiXiT for image classification (PiXiT also implements the same "Segment and Combine" idea but for audio signal classification, please contact us to get support with this type of data).
The goal of this software is: given a set of labeled images into one class among a finite number of classes (learning set), build an image classifier (model) that could be used to predict the class of any new, unseen image. The software learn to discriminate image classes.
Prepare image files and directories
You are supposed to have a set of images labeled into classes,
with one directory for each class. The name of the directory is the
name of the class. Image file names are not important.
For example, for the ZuBuD problem with 201 classes (object1 ... object201), it should look like this:
This software is working with Java 1.4.1 and higher. It is better to
expand the Java heap size with the -Xmx option to avoid OutOfMemory exception
when using large image databases (in terms of number of images and classes). For example, out of
memory may occurs when you build a model (if you don't see the "Extra Trees model 1" message after a while).
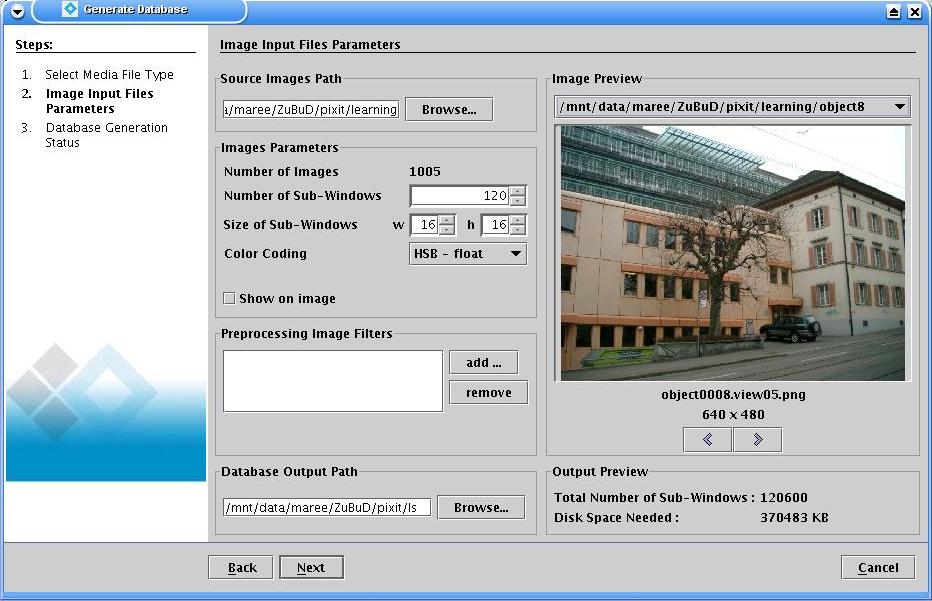
This step aims at extracting a large number of subwindows from learning images. The more is generally the better.
Later, this training sample will be used as input to the machine learning algorithm
to build a subwindow classification model. The default number of learning subwindows is 120000, with scale, in HSV encoding.
Browse and select the learning directory (Source Image Path). Image previews are shown on the right.
The choice of the optimal parameters (number of subwindows, transformations, color coding)
may depend on the problem and the way images were obtained. See our publications for details.
Select an output file (Database Output Path, eg: learningset) and then click Next to generate the learning database.
Build a classifier
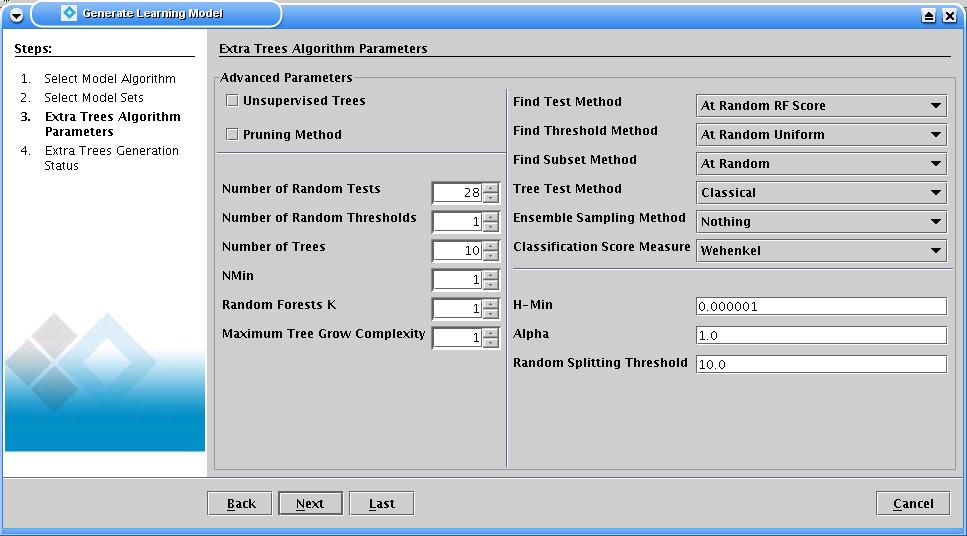
First, you have to load the generated learning database. Then click "Add Model",
Select "Extra Trees", Change "DefaultModelName" if you want, choose "Learning Set" (in the
classical way, the whole learning database is used).
In the method dialog window, default parameter are set to 10 trees. See our publications for more details. Build the model (learning time depends mostly on the number of subwindows, number of trees, and number of random tests).
Save it into one file (eg: model).
Generate a test database
Now you want to test the model on a new set of images.
You have to generate a test database in the same way than for learning.
It is recommended to
use the same subwindow parameters (multi-scale, multi-orientation or fixed) as
for the learning images. Extracting about 100 subwindow for each test image is
generally enough, the more is generally the better.
Browse and select the test directory. Select an output file (eg: testset) and
then generate the test database.
Note that there should be the same number of directory with same names than
for learning. Directories can be empty (if there is no test image from one class).
Test a classifier
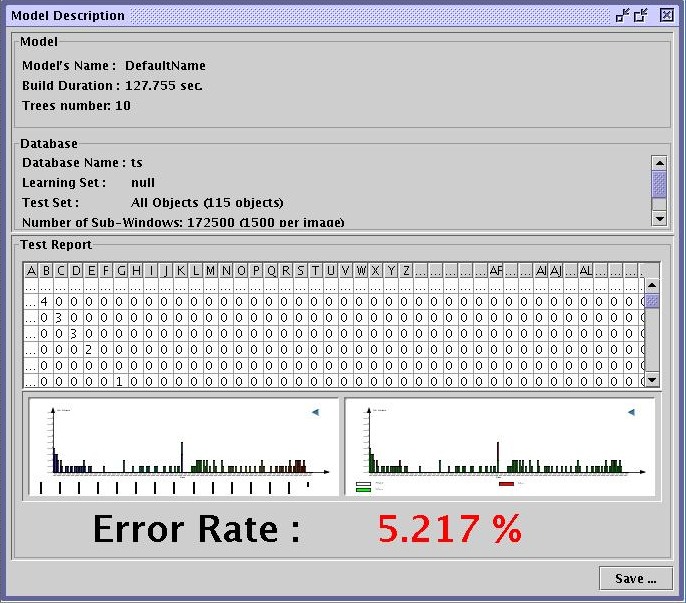
Load the test database. Load the model. Test the model.
Results are given in terms of misclassification error rates, confusion
matrix and classification histograms.
Note that it is also possible to apply the model on individual images.
Download
This software is distributed as a Java jar file. Please e-mail us to get access to the download area and to get a license file.In your e-mail request, please specify the name of your institution/company and describe briefly the image classification problem you will be working on. Feel free to contact us in french or in english.
By downloading the software, you accept these agreements and entitlements:
to inform us of the problem you are working on as
well as of your results, because the existence of new datasets/problems often
drives research forward
in case of publications, mention the use of our software and algorithms, and
send us a copy of the publication
not to use the software for commercial applications without our agreement
not to transfer the license to a third party without our agreement
Up to now, the software was distributed to more than 60 people worldwide (China, Russia, France, Belgium, USA, India, Canada, Italy, Greece, Turkey, Finland, Libya, ...)
To Do and known bugs
Known bugs
Some users experimented a bug with the user interface. The first time the software is used, after the generation
of a database, the loading of the database seems stalled (the "loading database" message never disappears). In fact,
the database is loaded after a reasonable time, but there is a panel on the left side of the PiXiT screen that does not expand itself as it should do. Moreover, the "loading" message never disappears. We observe this behavior with only some version of the Java virtual machine and we recommend you to update to the last version of the JVM. If the problem still occurs, you have to expand the panel manually from left to right with the mouse cursor. Once you have expanded it, this bug will not appear in the following executions of the software.
If the software is going wrong or if it does not do what you expected, please contact us, we'll provide you free support during the evaluation period.
To do list
Some missing features or optimization we are aware of:/p>
"best" (discriminant) subwindow viewer
cache for bigger subwindow datasets
compress trees on disk
If you have other ideas or wishes, please contact us.
The software is licensed exclusively to PEPITe for its commercial release.
This trial software is freely available for evaluation and non-commercial purpose.
Some options are missing, others may not work. You should consider this as a demo
software, not a final release.
You should contact us for any commercial or professional use.
This program is distributed in the hope that it will be useful, but without any warranty.
You have the permission to use but not redistribute the software neither the license file.
If you are using the software in a demo or in a paper, you must reference one of our paper (see publications), our webpage, and PEPITe. This could be done in your Acknowledgments section. Also, we want to be informed of any use of this software and of your (successfull or not) results.
Contact
You may have many good reasons to contact us. So feel free to do so in french or in english.
First, any comments are welcome. About the software, its (missing) options, its user interface, this webpage, ...
We would be pleased to know on which image classification problems you are working on and to know the results you obtained with this
software. If you are not satisfied, give us details about your problem
and the parameters you used, we could perhaps help you to tune them.
If you are interested to implement the software into your industrial or commercial environment,
PEPITe is the best partner as they know how
the software works and how to tailor it for your application. Note that PiXiT is the brother/sister of PEPITo, a whole Data Mining software.
 (ZuBuD)
(ZuBuD) (WANG)
(WANG) (COIL-100)
(COIL-100) (ORL)
(ORL)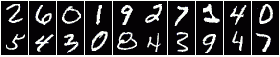 (MNIST)
(MNIST) (OUTEX)
(OUTEX)